Linux to system, który nieustannie ewoluuje – czasem w sposób spektakularny, a czasem w miejscach, których przeciętny użytkownik nigdy nie zobaczy. Jedną z takich zmian, która może znacząco wpłynąć na wydajność systemu, jest wprowadzenie mechanizmu Sheaves w jądrze Linux 6.18 . Brzmi tajemniczo? Zanurzmy się w techniczne szczegóły i odkryjmy, dlaczego to rozwiązanie może być przełomowe. 🐧
Co to są „Sheaves”?
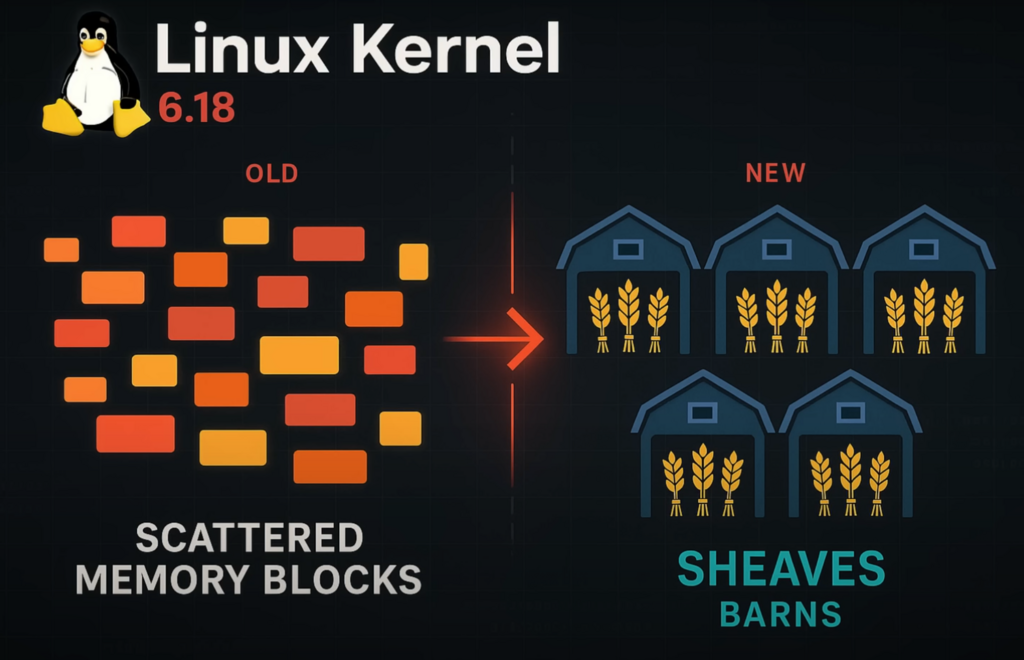
„Sheaves” (z ang. „snopy”) to nowa warstwa cache’owania w alokatorze pamięci SLUB – jednym z mechanizmów zarządzania pamięcią w jądrze Linux. W skrócie, chodzi o optymalizację alokacji obiektów w pamięci dla każdego CPU z osobna, zamiast korzystania z współdzielonych struktur, które mogą powodować blokady i spowolnienia.
Technicznie rzecz ujmując:
- Sheaves to opcja opt-in dla cache’ów pamięci, która tworzy tablicową warstwę cache per CPU.
- Każdy rdzeń procesora otrzymuje swój własny „snop” obiektów gotowych do alokacji i zwolnienia.
- Dzięki temu zmniejsza się potrzeba synchronizacji między rdzeniami – co przekłada się na mniej blokad (locks) i większą wydajność2.
Różnice względem poprzednich rozwiązań
Przed Sheaves, SLUB korzystał z tzw. partial slabs – struktur współdzielonych między rdzeniami, które wymagały synchronizacji przy alokacji i zwalnianiu obiektów. To działało dobrze… do czasu.
W systemach z wieloma rdzeniami (np. serwery, stacje robocze), współdzielenie tych struktur prowadziło do:
- zawężeń wydajności (CPU czekały na dostęp do zasobów),
- częstych operacji atomowych, które są kosztowne czasowo,
- spadków wydajności w intensywnych scenariuszach, np. przy pracy z VMA (Virtual Memory Areas) czy drzewami maple.
Sheaves eliminują te problemy, oferując:
- alokację bez operacji atomowych dzięki
local_trylock(), - lepsze wsparcie dla
kfree_rcu()– obiekty są grupowane i zwalniane hurtowo, co poprawia efektywność, - kompatybilność z NUMA, slub_debug i innymi funkcjami SLUB.
Jak debugować zjawiska i zachowania kernela Linuxa ze SLUB?
SLABDBG – rozszerzenie do otwartego debuggera DBG
(gdb) slab list
name objs inuse slabs size obj_size objs_per_slab pages_per_slab
ext4_groupinfo_4k 28 28 1 144 144 28 1
ip6_dst_cache 10 1 1 384 384 10 1
UDPLITEv6 0 0 0 1088 1072 -1 -1
UDPv6 15 0 1 1088 1072 15 4
tw_sock_TCPv6 0 0 0 272 264 -1 -1
request_sock_TCPv6 0 0 0 328 320 -1 -1
TCPv6 0 0 0 2048 2032 -1 -1
nf_conntrack_1 0 0 0 320 312 -1 -1
ashmem_area_cache 13 3 1 312 312 13 1
---Type <return> to continue, or q <return> to quit---qSALT – bardziej narzędzie do szukania podatności, ale również ciekawe!
> salt help
Possible commands:
filter -- manage filtering features by adding with one of the following arguments
enable -- enable filtering. Only information about filtered processes will be displayed
disable -- disable filtering. Information about all processes will be displayed.
status -- display current filtering parameters
add process/cache <arg>-- add one or more filtering conditions
remove process/cache <arg>-- remove one or more filtering conditions
set -- specify complex filtering rules. The supported syntax is "salt filter set (cache1 or cache2) and (process1 or process2)".
Some variations might be accepted. Checking with "salt filter status" is recommended. For simpler rules use "salt filter add".
record -- manage recording features by adding with one of the following arguments
on -- enable recording. Information about filtered processes will be added to the history
off -- disable recording.
show -- display the recorded history
clear -- delete the recorded history
trace <proc name> -- reset all filters and configure filtering for a specific process
walk -- navigate all active caches and print relevant information
walk_html -- navigate all active caches and generate relevant information in html format
walk_json -- navigate all active caches and generate relevant information in json format
help -- display this messageBenchmarki mówią same za siebie
W testach mikrobenchmarkowych w jądrze:
- Przy alokacji i zwalnianiu 100 obiektów, Sheaves dają wzrost wydajności o 31% (bez memcg) i ~25% (z memcg).
- Nawet przy małych partiach (1–10 obiektów), zyski wynoszą 11–17%.
To nie są kosmetyczne zmiany – to realne przyspieszenie działania systemu w krytycznych obszarach!
Ciekawostka: skąd nazwa „Sheaves”?
Nazwa „Sheaf” została zaproponowana przez Matthew Wilcox, jako alternatywa dla historycznego terminu „magazine” używanego w SLAB. Aby uniknąć skojarzeń z klasycznym podejściem Bonwicka, wybrano bardziej świeże i obrazowe określenie – „snop” obiektów. Co więcej, cache współdzielony dla węzła NUMA nazwano… „barn” (stodoła). Tak, kernel może być poetycki. Oto źródłowy materiał na ten temat.
Dlaczego to ważne dla użytkownika?
Choć Sheaves to zmiana głęboko techniczna, jej wpływ może być odczuwalny wszędzie:
- Szybsze działanie systemu w środowiskach wielordzeniowych,
- Lepsza skalowalność dla kontenerów i maszyn wirtualnych,
- Mniejsze zużycie CPU przy intensywnych operacjach pamięciowych.
To kolejny krok w kierunku uczynienia Linuksa jeszcze bardziej wydajnym i gotowym na przyszłość.
Podsumowanie
Sheaves to nie tylko nowa funkcja – to przemyślana ewolucja mechanizmu SLUB, która rozwiązuje realne problemy wydajnościowe. Jeśli interesujesz się jądrem Linuksa, to warto śledzić rozwój tej funkcji – szczególnie że może stać się domyślnym rozwiązaniem w przyszłych wersjach.
A jeśli jesteś fanem Linuksa – pamiętaj, że nawet „snopy” mogą zrobić różnicę w Twoim systemie Linux 🐧.